
Thomas Steckler
The views expressed in this presentation are solely those of the
individual authors, and do not necessarily reflect the views of their
employers.
Statistical power, importance of
effect sizes, and statistical
analysis
Information Meeting for Grant Applicants on the Call for
Proposals for Confirmatory Preclinical Studies and Systematic
Reviews - Quality in Health Research, Feb 19, 2019

2
Phillippe Vandenbroeck et al. (2006)
J Biopharm Statistics 16, 61-75

3
Underpowered Studies – A Common
Observation
Median Power of Studies Included in
Neuroscience Meta-Analyses
Included in the analysis were articles published in 2011 that described at least one meta-analysis of previously
published studies in neuroscience with a summary effect estimate (mean difference or odds/risk ratio) as well
as study level data on group sample size and, for odds/risk ratios, the number of events in the control group.
Studies with low statistical power
have:
• Reduced chance of detecting a true
effect
• Low likelihood that a statistically
significant result reflects a true
effect
• Overestimated effect sizes
• Low reproducibility
low
(57 %)
intermediate
(29 %)
high
(14 %)
Button et al., Nature Rev Neurosci, 2013

Power as function of animal
number
power
4
Another Consequences of Underpowered
Studies: Violation of the 3Rs
Adapted from M Macleod
5
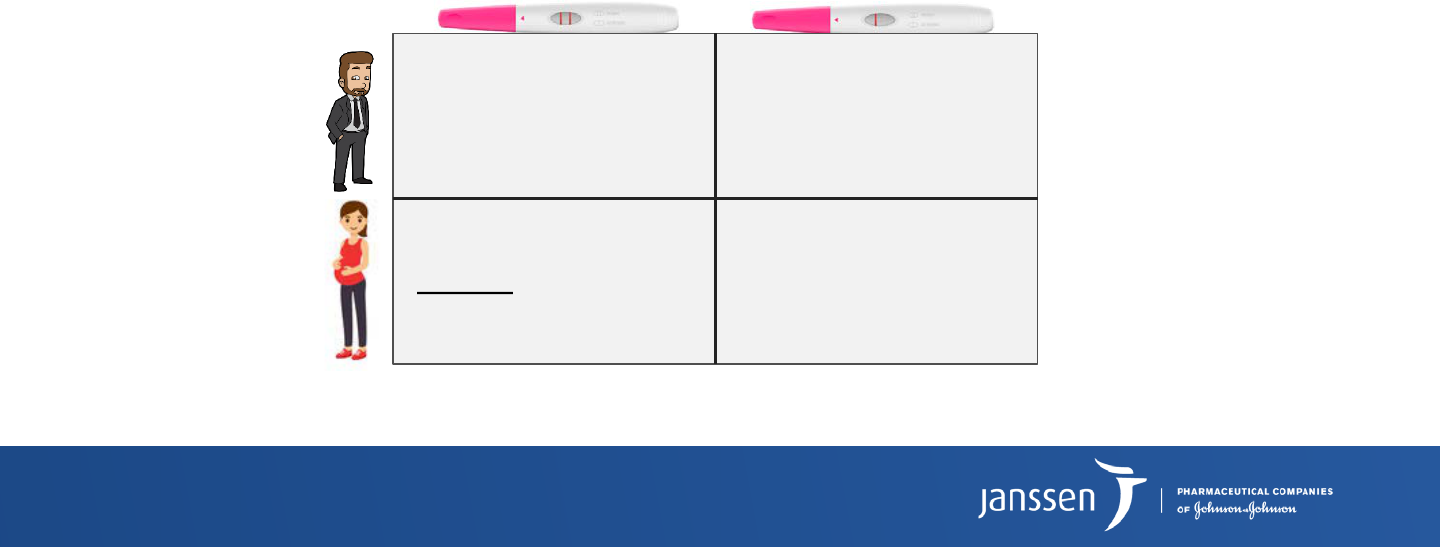
What is Power?
1 –
β
Probability to correctly reject
H
0
Probability to avoid a Type II error or a false negative
Chance to correctly detect a difference (Sensitivity)
Test result
Pregnant
Not pregnant
Reality
P(false positive)
Type I error
α
P(correct negative)
(Specificity)
1 -
α
P(correct positive)
Power (Sensitivity)
1 -
β
P(false negative)
Type II error
β

6
Statistical Hypothesis Testing
H
0
: Null Hypothesis
H
1
: Alternative Hypothesis
α
: P(false positive)
β
: P(false negative)
1-β
: P(correct positive)
μ
: Population mean
σ
: Population variance
Δ
: Effect size
Normal Distribution of
H
0
and
H
1

7
Statistical Hypothesis Testing
What is the probability of your data showing the observed difference
when in reality there is no difference (i.e.,
μ
1
–
μ
0
= 0)?
–
p
- values describe these probabilities
̶ A formal decision-making process that ensures false positives (or Type I error,
α
)
occur only at a predefined rate
̶ The smaller the
p
-value, the lower the probability that there is a false positive
̶ NOT the probability that an observed finding is true
̶ NOT implying a biologically meaningful effect
– Statistical significance if
p
< 0.05
̶ Means that if there is a false positive rate below
α
= 5%, we are willing to reject H
0
̶ Is an arbitrary convention, not a fundamental principle

8
What Makes a P-Value?
p
is a value computed by a statistical test (and may differ
according to the test used)
There is a mathematic relationship in any data set between:
– Accepted significance level (
α
), and hence
p
-value
– Observed/desired effect size (
Δ
)
– Variability within tested sample (standard deviation;
σ
)
– Sample size (
n
)
Changing one factor will affect the others

Type 2 error (
β
) will decrease as a function of sample size
Power (1-
β
) will increase as a function of sample size
Sampling mean variability will decrease as a function of sample size
9
Relevance of Sample Size for Power
± 1
σ
Δ
1-
β
β
α
μ
0
μ
1
H
0
H
1
± 1
σ
Type I error
Type II error
Power
n = 5
1-
β
β
n
= 10

10
Sample Size is Where You Randomize!
Sample size = number of experimental units per group
Experimental unit: entity subjected to an intervention
independent of all other units
Observational unit: entity on which measures are taken
(primary) outcome measure
Biological unit: entity about which inferences are made

11
Example Teratogenicity Study
Regulatory requirement as part of drug development program
Q: Does treatment X have embryotoxic or teratogenic effects?
Study design:
Susan B. Laffan, Teratology Primer, 3rd Edition

12
Example Teratogenicity Study
Biological unit:
– The offspring (do fetuses show abnormalities?)
Observational unit:
– Observations made in the offspring during external, visceral and
skeletal examination
– E.g., fetuses with branched ribs
Experimental unit:
– The litter, not the individual fetuses!
– (entity subjected to an intervention
– independent of all other units)
OECD and ICH do not allow offspring to
be used as independent samples!
Pseudo-replicates

13
Why is Power Important?
There is no difference (true negative)
The study failed to detect that difference (false negative)
A study may not show a difference between groups because:
https://www.youtube.com/watch?v=SRyP2BPGUgg

14
Issues with Low Power
Potentiation by Bad Practice
1000 hypotheses
10% true → n = 100
Publication
Bias
65 experiments published
69% false positives
Power 0.8:
125 experiments published
36% false positives
False positive rate
α
= 0.05
5% → n = 45
Power = true positive rate = 0.2
20% → n = 20
False negatives
80% → n = 80
Adapted from The Economist, 2013

15
Strategies Used Along the Discovery
Chain
Target
Identification
Target
Validation
Hit
Identification
Hit to
Lead
Lead
Optimization
NME
Declaration
EXPLORATORY /
SCREENING
HYPOTHESIS TESTING /
CONFIRMING
• Absence of a scientifically plausible hypothesis
• Methods can be adapted (to some degree)
•
p
-values cannot be interpreted at face value
• A scientifically plausible hypothesis exists
• Requires pre-specification of
H
0
,
experimental methods incl. sample size and
analytical methods
• Leads to a statement of significance
Elements can be combined
• Confirmatory for primary (and key secondary) endpoint
• Exploratory for other endpoints

16
Strategies Used Along the Discovery
Chain
Target
Identification
Target
Validation
Hit
Identification
Hit to
Lead
Lead
Optimization
NME
Declaration
Type I error
tolerance
Need for high
sensitivity
• Look for strong effects
• Importance to discover potential early on
• Discovery of false positives less serious
• Primary risk with the company
• Look for true effects
• Avoid exposure of patients to non-active therapy
• Only invest in development of efficacious therapy
• Risk of the company and of authorities
Power
low
high

Thomas Steckler
The views expressed in this presentation are solely those of the
individual authors, and do not necessarily reflect the views of their
employers.
Statistical power, importance of
effect sizes, and statistical
analysis
Information Meeting for Grant Applicants on the Call for
Proposals for Confirmatory Preclinical Studies and Systematic
Reviews - Quality in Health Research, Feb 19, 2019

18
Other Ways to Affect Power
Adapted from F Tekle
n
= 5
σ
= 1.7
α
= 0.05
Δ
= 0.1
1-
β
Chose a different significance level
(
α
)
α
= 0.1
1-
β
Change variability within a sample
(
σ
)
σ
= 3.4
1-
β
Alter the effect size (
Δ
)
Δ
= 0.05
1-
β

19
The Different Factors Interact
Smaller effect sizes require larger
sample sizes
Measures with large variability require
larger sample sizes
Adapted from F Tekle

Increasing Sample Size Can Make a
Result Significant
20
control
manipulation
0.0
0.5
1.0
1.5
Low variability
unit
x=0.970 x = 1.026
n
= 5
σ
= ±0.046 vs. ±0.045
p
= 0.411 in t-test
control
manipulation
0.0
0.5
1.0
1.5
Very low variability
unit
x=0.970 x = 1.026
n
= 5
σ
= ±0.007 vs. ±0.005
p
= 0.002 in t-test
*
control
manipulation
0.0
0.5
1.0
1.5
Low variability, but large n
unit
x=0.970 x = 1.026
n
= 25
σ
= ±0.046 vs. ±0.045
p
= 0.039 in t-test
*
But is it meaningful?
Adapted from M. Michel, 2017
Hypothetical Data Set

21
What is a Meaningful Effect?
If sample size is too high and desired effect size is not defined, there is an
increased risk
– of making a false positive conclusion (Literature is full of it!)
– that statistically significant effects are declared that are of no practical relevance
– that resources are wasted
– of ethical issues (e.g., in case of animal studies)
A desired effect
– should be relevant (scientifically, clinically, economically,…)
– should be determined upfront (which effect must be detectable to make the study
relevant?)
– should be documented (to avoid bias)
– is a choice by the researcher
– based on estimation or experience, not statistically determined
– but will affect statistics!

22
Exploration of sample size sets of
n = 10, 20, 30, 50, 85, 170, 500,
and 1000, drawn from a
multivariate normal distribution
1,000 studies simulated per n
True effect size arbitrarily set to
Δ
= 0.3
To obtain 80% power for
Δ
=0.3
requires 85 samples
Jim Grange (2017)
https://jimgrange.wordpress.com/2017/0
3/06/low-power-effect-sizes/
Low Sample Size Inflates Measured
Effect Sizes

→low power and high FDR
23
False Discovery Rate vs. Positive
Predictive Value
Positive predictive Value (PPV)
– Probability that a real effect exists if a “significant” result has been obtained
False Discovery Rate (FDR)
– Probability that a real effect does NOT exist if a “significant” result has been obtained
PPV and FDR are flipsides of the same coin (FDR = 100 – PPV)
A research finding is less likely to be true in case of
Small studies
Small effect sizes

Unintended Flawed Procedures Impact
Data Quality
24

Thomas Steckler
The views expressed in this presentation are solely those of the
individual authors, and do not necessarily reflect the views of their
employers.
Statistical power, importance of
effect sizes, and statistical
analysis
Information Meeting for Grant Applicants on the Call for
Proposals for Confirmatory Preclinical Studies and Systematic
Reviews - Quality in Health Research, Feb 19, 2019

26
Sample Size Affects Sampling Distribution
Hence Statistical Approach
Central Limit Theorem
For a random sampling with a large
n
, the sampling distribution is
approximately normal, regardless of the underlying distribution
Note also tests for normality will struggle if the sample size is small
Simulated data set of a skewed distribution:
1,000 randomly drawn samples for sample sizes
n
=10 and
n
=50
As the sample size increases, and the number of samples taken remains constant, the distribution of the 1,000 sample
means becomes closer to the smooth line that represents the normal distribution
https://archive.cnx.org/contents/323cb760-5f99-4899-a96b-f3919f982a6a@10/using-the-central-limit-theorem#eip-id1169478792440

27
What is the Right Power?
Cohen (1988) proposed as a convention that, when the investigator has no
other basis for setting the desired power value, the value .80 be used
Rationale:
1. α
/
β
Interrelationship:
if 1-
β
increasing→
β
decreasing →
α
increasing
(effect size and sample size being unchanged)
2. Relative error seriousness: Scientists usually consider false positive claims
more serious than false negative claims
if
α
= .05 and
β
= .20 → relative seriousness = .20/.05
1. (i.e., seriousness of Type I errors = 4 x seriousness of Type II errors)
3. Feasibility: Power >.90 would demand very large sample sizes
if 1-
β
increasing and
α
constant → needs increasing effect size (may not be feasible)
or
increasing sample size
Cohen J (1988) Statistical Power Analysis for the Behavioral Sciences, 2
nd
ed.,
Lawrence Erlbaum Associates
There may be reasons to divert from the convention

28
How to Get to the Right Sample Size?
Based on the given variability and the expected difference between the
effect of manipulation X and the effect of the control groups a minimum
number of samples is required
Variability:
– Should be provided in standard deviation units (
σ
)
– Can be estimated from pilot studies or data reported in the literature
– Can be calculated from SEM and
n
:
σ
= SEM ∗ √
n
Effect size (Cohen’s
d
):
– Potential mean difference between any two groups in terms of standard deviation
units
– Signal (effect size of scientific interest)/noise (variability)
– Can be estimated from pilot studies or data reported in the literature
– Convention: small (
Δ
= 0.2), medium (
Δ
= 0.5), large (
Δ
= 0.8)*
– If in doubt, hypothesize a
Δ
= 0.5
*based on benchmarks by Cohen (1988)
may be larger in case of animal studies: small (d = 0.5), medium (d = 1.0), large (d = 1.5)

29
Power Depends on Experimental Design
and Statistical Analysis
Example: Two independent samples, comparing two means
Analysis: unpaired T-test
– T-test can be one- or two-tailed (two-tailed preferred)
can be paired (dependent samples) or unpaired (independent samples)
Assumption: comparison of two independent samples of equal
n
– Equal-sized samples are desirable, since it is demonstrable that with a given
number of cases available, equal division yields greater power than does unequal
division
Sample size calculation (one-tailed):
n
= (
Z
α
+
Z
1-
β
)
²
∗ 2
σ
²
/
Δ
²
with
Z
α
= constant according to accepted
α
level [100(
α
) percentile of the standard normal distribution],
depending on whether test is one- or two-tailed (in the latter case would be
Z
α/2
)
Z
1-
β
= constant according to power of the study [100(1-
β
) percentile of the standard normal distribution]
σ
= common population variance
Δ
= estimated effect size

30
Common population variance:
σ
= √(
σ
1
²
+
σ
2
²
) / 2
C
ohen’s
d
:
Δ
= (
μ
1
+
μ
2
) /
σ
Z
-values for T-test:
Z
α
& Z
α
/2
Z
1-
β
with
σ
1
= standard deviation control group
σ
2
= standard deviation experimental group
with
μ
1
= mean of control group
μ
2
= mean of experimental group
α
0.01 0.05 0.1
Z
α
2.326 1.645 1.282
Z
α
/2
2.576 1.960 1.645
1 - β
0.8 0.90 0.95
Z
1-
β
0.842 1.282 1.645
one-tailed
two-tailed

31
Finally: Software for Sample Size
Calculation
G*Power
– http://www.gpower.hhu.de
– Stand-alone program
– Windows, Mac
– Free
PASS
– https://www.ncss.com/software/pass
– Stand-alone program
– Windows
– Not freely available
Various R packages
– Windows, Mac, Linux
– Generally free
SAS, SPSS, Minitab, Microsoft Excel packages
NC3Rs Experimental Design Assistant (EDA)
– https://eda.nc3rs.org.uk/experimental-design-group
– Free
If in doubt, ask your STATISTICIAN !

32

33
Know Your Research Question
Research Question:
Does Intervention X (I
X
) alter the Primary Outcome Measure Y (POM
Y
) ?
increase
decrease
increase or decrease
Null Hypothesis (H
0
):
I
X
has NO effect on POM
Y
Alternative Hypothesis (H
1
):
I
X
has an effect on POM
Y
directional (one-sided)
non-directional (two sided)

34
The Protocol
Research Protocol
Describes design logic and
forms the basis for reporting
Research question
Alternative hypothesis
Experimental design rationale
Measures to minimize bias
Choice of clinical model
Operationalization of responses
Execution Protocol
Describes practical actions
Guidelines for lab techs
Intervention
Materials
Logistics
Data collection & processing
Personnel, responsibilities
Reflects the various layers in the design and execution of the experiment
Statistical Protocol
Describes design & analysis
methods
Specific designs chosen
Power calculations
Description of the statistical
model and tests used
Adapted from L. Bijnens, 2017

Mean, S
D
and SEM for three samples increasing size
n
=1 to
n
=100
Adapted from F Tekle
Relevance of Sample Size

36
Power Analysis
A-priori
•What do I need for my experiment and is it feasible?
•What sample size is needed to detect a difference at predefined effect size, anticipated variability
and with a certain probability, given that this difference indeed exists?
•What sample size is needed to detect a difference at predefined effect size, anticipated variability
and with a certain probability, given that this difference indeed exists?
•Will I be able to run this experiment?
•Can I get enough samples?
•Can I test all the samples?
•Can I afford the experiment?
•If not, does it still make sense to run the experiment?
Post-hoc
•How reliable are the data (reported)?
•What was the power of a reported study, given the observed effect size, variability and number of
samples reported?
•Can I “trust” the data?

Underpowered Studies – Still an Issue 5 Years Later
Efficacy of Analgetics
Effect of drug interventions in models of chemotherapy-induced peripheral neuropathy
Systematic search, inclusion of 341 publications by Nov 2015
Outcome measure Model (examples) Number
comparisons
Post-hoc
power
Evoked limb withdrawal to
mechanical stimuli
e.g., electronic "von Frey", mechanical monofilament, pin
prick, pinch test
648
0.06
Evoked limb withdrawal or
vocalisation to pressure
e.g., Randall-Selitto paw pressure 235
0.07
Evoked limb withdrawal to
cold
e.g., acetone/ethylchloride/menthol, cold plate, cold water 251
0.06
Evoked limb withdrawal to
heat
e.g., radiant heat, hot plate, paw immersion 140
0.07
Evoked tail withdrawal to cold e.g., tail immersion 50
0.06
Evoked tail withdrawal to heat e.g., tail flick, tail immersion 38
0.19
Complex behaviour, pain-
related
e.g., TRPA1 agonist- or capsaicin-evoked nocifensive
behavior, burrowing activity, CPP, thermal place preference
12
0.10
unpublished data, based on Currie et al., bioRxiv, 2018, http://dx.doi.org/10.1101/293480, courtesy of Ezgi
Tanriver-Ayder, Gillian L. Currie, Emily Sena

38
More Likely for a Research Claim to be
False Than True
A research finding is less likely to be true in case of
– Small studies
– Small effect sizes
– Many statistical comparisons, less pre-defined criteria
– Greater flexibility in designs, definitions, outcomes, and analytical modes

39
Example: Phenotypic Screen
Test population
10,000 compounds from
compound library
Real effect in 0.1%
(10 compounds
active)
No effect in 99.9%
(9990 compounds
inactive)
Power = 0.2
20%
(2 compounds) will
show as true
positives
80%
(8 compounds) will
show as false
negatives
95% (9490.5
compounds) will
show as true
negatives
5% (499.5
compounds) will
show as false
positives
Significance level = 0.05
What is the probability that there is no efficacy even if a “significant” result has been obtained?
FDR =
False Positives ( )
Modified from Colquhoun (2015) R Soc Open Sci 1: 140216
P(real) = 0.001 (1/1000 cpds have an effect)
Assumptions:
• Pre-existing compound
library
• On average, 1/1000
compounds will be active

False Positives ( )
40
Example: Phenotypic Screen
Test population
10,000 compounds from
compound library
P(real) = 0.001 (1/1000 cpds have an effect)
Real effect in 0.1%
(10 compounds
active)
No effect in 99.9%
(9990 compounds
inactive)
Power = 0.2
20%
(2 compounds) will
show as true
positives
80%
(8 compounds) will
show as false
negatives
95% (9490.5
compounds) will
show as true
negatives
5% (499.5
compounds) will
show as false
positives
Significance level = 0.05
What is the probability that there is no efficacy even if a “significant” result has been obtained?
FDR =
499.5
/
All Positives ( )
Assumptions:
• Pre-existing compound
library
• On average, 1/1000
compounds will be active
Modified from Colquhoun (2015) R Soc Open Sci 1: 140216

+
499.5
All Positives ( )
False Positives ( )
41
Example: Phenotypic Screen
Test population
10,000 compounds from
compound library
P(real) = 0.001 (1/1000 cpds have an effect)
Real effect in 0.1%
(10 compounds
active
No effect in 99.9%
(9990 compounds
inactive)
20%
(2 compounds) will
show as true
positives
80%
(8 compounds) will
show as false
negatives
95% (9490.5
compounds) will
show as true
negatives
5% (499.5
compounds) will
show as false
positives
Significance level = 0.05
What is the probability that there is no efficacy even if a “significant” result has been obtained?
FDR =
499.5
2
= 0.99.6 (99.6%)
→ > 99% of compounds are falsely detected as “active”
Assumptions:
• Pre-existing compound
library
• On average, 1/1000
compounds will be active
Power = 0.2
/
Modified from Colquhoun (2015) R Soc Open Sci 1: 140216

All Positives ( )
10
+
False Positives ( )
42
Making Statistics More Robust
Test population
10,000 compounds from
compound library
P(real) = 0.001 (1/1000 cpds have an effect)
Real effect in 0.1%
(10 compounds
active
No effect in 99.9%
(9990 compounds
inactive)
80%
(8 compounds) will
show as true
positives
20%
(2 compounds) will
show as false
negatives
99.9% (9980
compounds) will
show as true
negatives
0.1% (10
compounds) will
show as false
positives
Significance level = 0.001
What is the probability that there is no efficacy even if a “significant” result has been obtained?
FDR =
10
8
= 0.55 (55%)
→ 55% of compounds are falsely detected as “active”
Assumptions:
• Power increased to 0.8
• α set to 0.001
Power = 0.8
/
Modified from Colquhoun (2015) R Soc Open Sci 1: 140216

43
Example Cell Culture
Cells suspended and pipetted into wells of microtiter plate, treatment
randomized to wells, replicates on multiple days
→ EU: the well, not the individual cells (possible)
→ the replicates, not the wells (better!)
could be well plates run on one day would be subsamples
improves robustness / consistency / generalizability
becomes a scientific judgement!
Day 1
Day 2
• Experimental material (cells) are artificially
homogenous
• Experimental conditions very narrowly
defined

44
Multiple Interventions 1
Example 1: New drug against vehicle and multiple active comparators
Q: do drugs differ from vehicle and when compared to each other?
Multiple (
m
) interventions, independent samples, multiple comparisons (comparing more then 2 means)
Stats: curve fitting if possible (e.g., to calculate and compare EC
50
’s)
– often not possible →ANOVA (overall effect), post-hoc test (pairwise comparisons of all conditions with
– each other)
Sample size calculation similar to unpaired T-test
▪ Take desired effect size
▪ Calculate population variance
▪ Use Z-values for T-test
Balanced design, comparisons estimated best if same number of
samples are allocated per group

45
Multiple Interventions 2
Example 2: Dose-response study with planned comparisons
Q: is drug X active when compared to vehicle?
Multiple (
m
) interventions , independent samples, 1 control, pairwise comparisons
Stats: ANOVA (overall effect), planned comparisons (individual drug doses vs. vehicle)
Sample size calculation similar to unpaired T-test
But: Number of samples in control group should be √
m
– times the number of samples
in intervention groups
(Bate & Karp, PLOS One, 2014)
N
c
= √
m ∗ n
m
with
N
c
= adjusted control group size
m
= number of interventions (e.g. drug doses tested)
n
m
= calculated sample size
Unbalanced design, gains sensitivity at cost of multiple comparisons

46
Multiple Interventions 3
Example 3: Comparison of 2 drugs, all samples receive all treatments
Q: is one drug better than the other drug?
Multiple (
m
) interventions , dependent samples
Stats: Cross-over design, repeated measures ANOVA
Sample size calculation uses same formula as for unpaired T-test
But: Variability used is the within sample standard deviation σ
w
σ
w
= √(WMSE), with WMSE = within mean square error from the ANOVA table

47
Special Cases and Additional Requirements
Large sample size due to high → consider covariates
variability → consider blocking factors
Anticipated dropouts → add samples
Studies designed to show lack of → need high power and
effect (zero-data)? variability (95% CI) covers
effect size too small to be
considered relevant
Other statistical approaches → ask your statistician!


49
How to Deal with…
High variability?
– Consider blocking factors
A variable that has an effect on an experimental outcome, but is itself of no interest
Age, gender, experimenter, time of day, batches…
– Use block designs to reduce unexplained variability
– Key concept: variability within each block is less than the variability of the
entire sample → increasing efficiency to estimate an effect
Treatments
Block 2 Block 1
Experimental units in one block
are more ‘alike’ than others


51
How to Deal with…
Studies designed to show lack of effect (zero-data)?
– Example: Attempt to confirm published work
Minimize false negatives! → Power >> .80!
Demonstrate result is conclusive! → Show effect size is less than
originally reported
Modified from: Bespalov et al., unpublished
A non-significant result may or may not be conclusive
-
d
min
+
d
min
if 95% confidence interval
overlaps with important effect we
cannot exclude possibility that
there is an important impact
groups not different, but also not
equivalent
groups not difference and equivalent

What is convincingly negative?
High research rigor
• Robust and unbiased experimental design, methodology, analysis, interpretation, and reporting
• Authors of original paper consulted (if possible)
Properly validated methods
No evidence for technical failure
Converging evidence on multiple readouts (if possible)
Ideally multi-lab collaborative effort
Adequate data analysis methods establish the observed results as statistically negative
• No experiment can provide an absolute proof of absence of an effect, i.e., p > 0.05 does not proof negative results
• Often more rigorous design and stronger statistical power required than in the original report (power of 0.2 is not sufficient!)
• Confidence intervals should be narrow and cover only those effect sizes that aren’t considered scientifically relevant
Full access to methods and raw data are provided
Results likely to have a significant impact if published
52

53
Choosing the Appropriate Power
Calculation
https://eda.nc3rs.org.uk/experimental-
design-group

54
Additional Strategies to Increase Power
Use as few treatment groups as possible
Investigate only main effects rather then interactions
Use direct rather than indirect dependent variables
Use sensitive measures
Use reliable measures
Use covariates and/or blocking variables
Use cross-over designs

{kind=link}